Table of contents
- Common Causes & Prerequisites: When Python Scripts Fail
- General Solution Approaches: Python Libraries Overview
- Recommended Robust Solution: Renee PDF Aide for Batch & Automation
- Alternative Method: Advanced Python Script for Custom Automation
- Verification & Recommendations
- Frequently Asked Questions (FAQ)
Summary
Converting PDFs to editable DOCX files using Python is a common task for developers and data analysts. While open-source libraries like pdf2docx, PyMuPDF, and pdfplumber offer flexibility, they often struggle with scanned documents, complex layouts, and embedded fonts. For reliable batch processing, built-in OCR, and hands-free automation, dedicated desktop tools like Renee PDF Aide provide a robust alternative that eliminates the need for extensive custom scripting.
Many developers and data analysts need to convert PDFs into editable DOCX files on a regular basis. PDFs are designed with a fixed layout that is perfect for viewing, but this rigidity makes converting them into flexible Word documents challenging.
Typical tasks involve batch-processing hundreds of reports or invoices, setting up overnight document workflows, or building automated data extraction pipelines. However, Python scripts often struggle with complex tables, embedded images, or scanned pages without a selectable text layer.
As a result, formatting often gets scrambled, native OCR is absent, and you are left with tedious scripting overhead. Features like built-in folder monitoring or simple scheduled execution require extra libraries and cron jobs.
This is a significant hurdle for developers, data analysts, freelancers, and anyone pursuing automation who needs reliable batch processing with timed or hands-off execution.
Common Causes & Prerequisites: When Python Scripts Fail
Pure Python approaches often hit limitations in production environments, so it is best to understand the common failure points before running a script.
| Issue Type | Typical Cause | Pre-check / Diagnosis |
|---|---|---|
| Scanned PDFs | No selectable text | Open the PDF and try highlighting text; if nothing highlights, OCR is required |
| Complex tables/layouts | pdf2docx doesn’t have a layout engine | Convert one page first and check for shifted columns |
| Embedded fonts / garbled text | Font subsetting or non-standard encoding | Scan the DOCX for □ or random symbols |
| Large batch crashes | Memory or dependency conflicts | Test with 5–10 files; keep an eye on RAM usage |
Pure Python approaches struggle with production batch automation. They demand significant custom code for layout preservation, OCR, and scheduling.

PDF text generates garbled characters while processing embedded fonts.
General Solution Approaches: Python Libraries Overview
| Approach | Best For | Key Limitation |
|---|---|---|
| pdf2docx | Quick conversions of digital PDFs | Weak with complex layouts; no OCR |
| PyMuPDF + python-docx | Full control and custom extraction logic | Requires heavy coding for layout reconstruction |
| pdfplumber | Table‑centric PDFs | No DOCX output; text extraction only |
| Pandoc | Scriptable pipelines; multi‑format workflows | PDF→DOCX quality depends on LaTeX/PDF readers |
| LibreOffice CLI | Batch automation; headless conversion | Layout fidelity varies; no OCR |
📘 pdf2docx
Built on PyMuPDF and python‑docx, maintained by Artifex Software and contributors.
Site: https://github.com/ArtifexSoftware/pdf2docx
Initial Release: Around 2020 (first commits and PyPI publication)
Latest Update: May 1, 2026 (v0.5.13)
Status: No longer actively maintained by Artifex; relicensed MIT for community use
| Feature | Support |
|---|---|
| Direct PDF→DOCX | Yes |
| OCR | No |
| Embedded Fonts | Partial |
| Complex Layouts | Moderate |
| Automation | Yes |
| XFA Forms | No |
Recent Reported Issues:
- Image rotation errors after conversion Github
- Hyperlink conversion bugs and invalid OOXML output Github
- Table conversion failures and misaligned text Github
- Compatibility problems with Python 3.12 and PyInstaller packaging Github
📘 PyMuPDF + python-docx
PyMuPDF (fitz) is developed by Artifex Software. It provides low‑level PDF access; python‑docx handles DOCX generation.
Site: https://pymupdf.readthedocs.io
Initial Release: PyMuPDF bindings appeared around 2016, based on the MuPDF engine
Latest Update: April 24, 2026 (v1.27.2.3)
Status: Actively maintained by Artifex Software, frequent releases and bug fixes
| Feature | Support |
|---|---|
| Direct PDF→DOCX | No (manual coding) |
| OCR | No (external OCR needed) |
| Embedded Fonts | Read only |
| Complex Layouts | High control, manual |
| Automation | Excellent |
| XFA Forms | No |
Recent Reported Issues:
- Formula rendering errors (black boxes) Github
- Dehyphenation broken in recent versions Github
-
Crashes on XFA forms when calling
page.widgets()Github - Segfaults with shared image xrefs across pages Github
📘 pdfplumber
Created by Jeremy Singer‑Vine, now community‑maintained. Focuses on text and table extraction.
Site: https://github.com/jsvine/pdfplumber
Initial Release: 2015 (first GitHub commits by Jeremy Singer‑Vine)
Latest Update: January 5, 2026 (v0.11.9)
Status: Community‑maintained, still receiving updates and bug fixes
| Feature | Support |
|---|---|
| Direct PDF→DOCX | No |
| OCR | No |
| Embedded Fonts | No |
| Complex Layouts | Good for tables |
| Automation | Yes |
| XFA Forms | No |
Recent Reported Issues:
- Table extraction failures on specific PDFs Github
- Incorrect parsing of last table rows Github
- ResourceWarnings due to unclosed file handles Github
- Coordinate inversion bugs in text bounding boxes Github
📘 Pandoc
Created by John MacFarlane, Pandoc is a universal document converter supporting 40+ formats.
Site: https://pandoc.org
Initial Release: 2006 (created by John MacFarlane)
Latest Update: March 19, 2026 (v3.9.0.2)
Status: Actively maintained, frequent releases with new format support
| Feature | Support |
|---|---|
| Direct PDF→DOCX | Yes (via LaTeX) |
| OCR | No |
| Embedded Fonts | No |
| Complex Layouts | Limited |
| Automation | Excellent |
| XFA Forms | No |
Reported Issues:
- Regression in LaTeX header‑includes causing PDF build errors Github
- Broken links in documentation and missing ICML references Github
- DOCX conversion losing bullets when images are present Github
📘 LibreOffice CLI
LibreOffice is maintained by The Document Foundation. Its headless soffice mode is widely used for batch conversions.
Site: https://www.libreoffice.org
Initial Release: 2010
Latest Update: June 5, 2026 (LibreOffice 26.2.4)
Status: Actively maintained by The Document Foundation, regular bugfix and feature releases
| Feature | Support |
|---|---|
| Direct PDF→DOCX | Yes |
| OCR | No |
| Embedded Fonts | Partial |
| Complex Layouts | Moderate |
| Automation | Excellent |
| XFA Forms | No |
Recent Reported Issues:
- Conversion failures in Docker/TrueNAS setups with fatal startup errors Github
-
Input filter problems (
--infilterargument required for PDF import) Github -
File not created errors (
ENOENT) during conversion Github
Recommended Robust Solution: Renee PDF Aide for Batch & Automation
If you are looking for reliable batch conversion, built-in OCR, and scheduled automation without endless script debugging, Renee PDF Aide is a standout desktop solution. It handles PDF to DOCX in Python workflows smoothly and addresses the pain points that most Python libraries leave behind.
- ✓ Convert to Editable Convert to Word/Excel/PPT/Text/Image/Html/Epub
- ✓ Multifunctional Encrypt/decrypt/split/merge/add watermark
- ✓ OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
- ✓ Quick Convert dozens of PDF files in batch
- ✓ Compatible Support Windows 11/10/8/8.1/Vista/7/XP/2K

Key Advantages Include
- Batch processing: Add multiple files with a single click and process hundreds of pages effortlessly.
- Speed: Convert up to 80 pages per minute.
- OCR for scanned PDFs: Three recognition modes extract text from scanned documents where pure Python solutions would fail.
- Automation-ready: Monitoring mode checks folders every 5 seconds for new files and supports scheduled tasks.
- Local privacy: Everything stays on your machine; no file uploads, ensuring full privacy.
- Output to DOCX: Direct Word conversion with reliable layout preservation.
Step-by-Step Operation
Prerequisite: Download and install Renee PDF Aide.

Step ①: Open Renee PDF Aide and select Convert PDF.

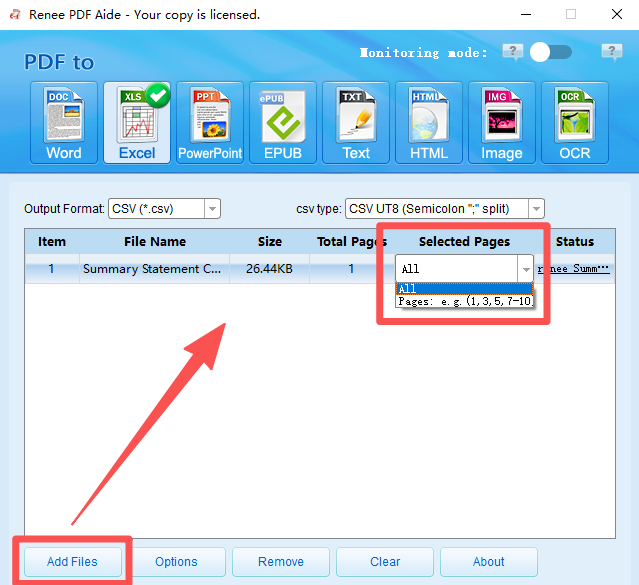
Step ②: Click Add Files to import one or more PDFs—batch conversion is built right in. If you only need specific pages, use Selected Pages to choose the range.
Step ③: From the top menu, select Word as the output format. Under Options, you can adjust layout preferences, such as keeping pages grouped or splitting them.
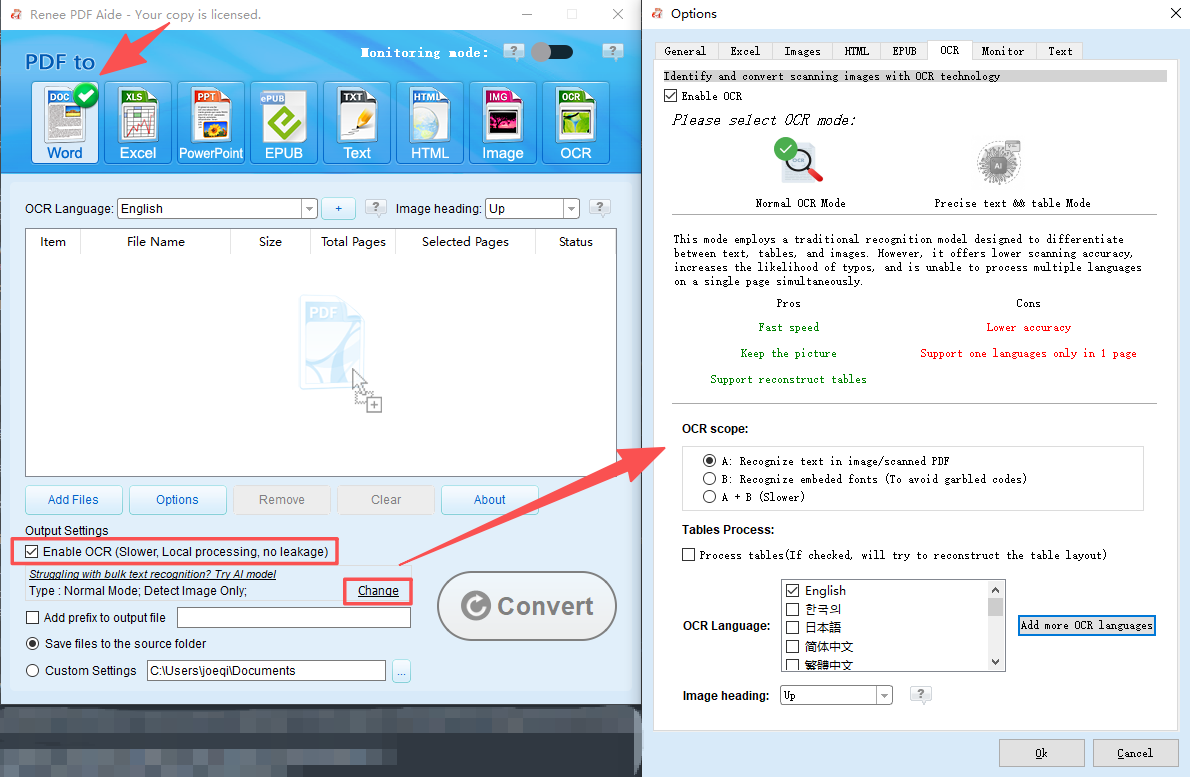
Step ④ (for scanned PDFs only): Enable OCR and select the appropriate mode:
- Mode A: Best for pictures or scanned images—select the document language for top accuracy.
- Mode B: Use for PDFs with embedded fonts to avoid garbled characters.
- Mode A+B: Auto-detection; handles mixed content at a slightly slower pace.
If your PDF already has selectable text, skip OCR entirely.
Step ⑤: Click Convert. Monitor the Status column. Once it displays ‘Success’, click the link to open each DOCX file.

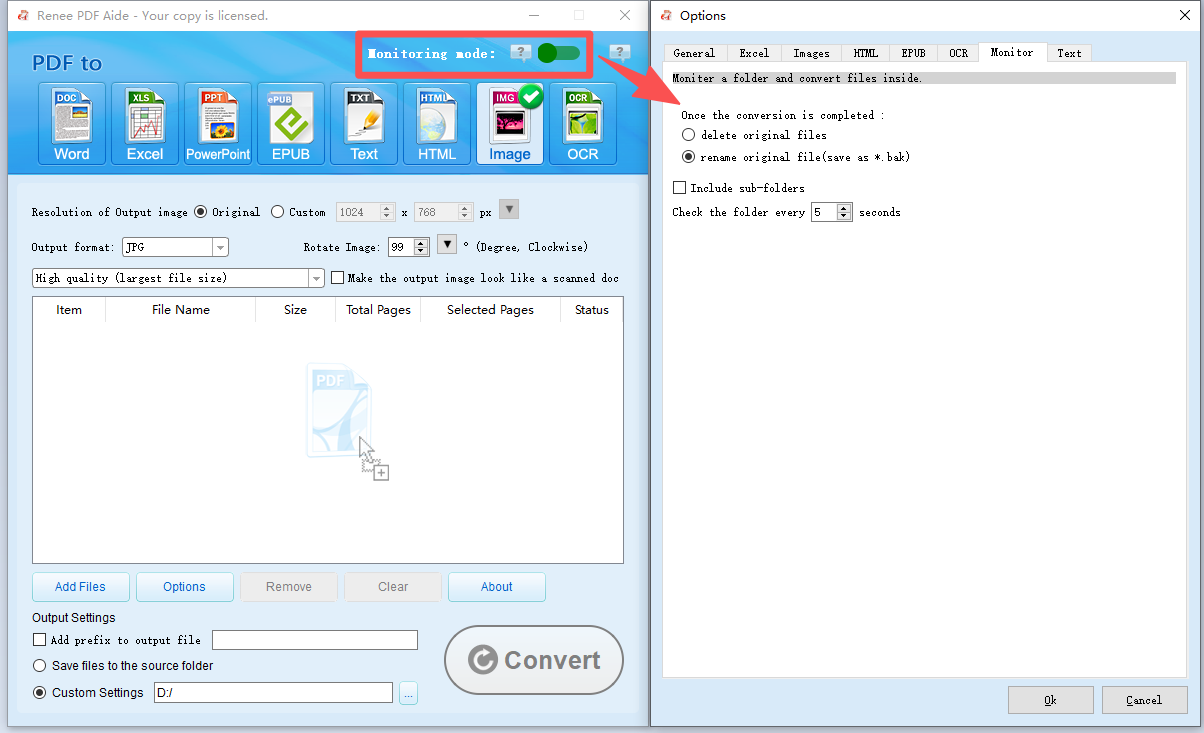
Monitoring Mode (Automatic)
To set up hands-free automation, enable Monitoring Mode. Select a target folder (including subfolders), and any new PDFs added will be converted automatically every 5 seconds using your chosen settings.
- ✓ Convert to Editable Convert to Word/Excel/PPT/Text/Image/Html/Epub
- ✓ Multifunctional Encrypt/decrypt/split/merge/add watermark
- ✓ OCR Support Extract Text from Scanned PDFs, Images & Embedded Fonts
- ✓ Quick Convert dozens of PDF files in batch
- ✓ Compatible Support Windows 11/10/8/8.1/Vista/7/XP/2K
Alternative Method: Advanced Python Script for Custom Automation
This approach is ideal when you want full control over the code and are working primarily with simple, native PDFs. Writing your own script allows you to integrate PDF conversion directly into an existing automation pipeline without a third-party GUI. Note: You will need a solid understanding of Python and the libraries that manage file system events.
Steps
Step 1: Install Dependencies
First, install the required libraries:
pip install pymupdf python-docx watchdog
Step 2: Write the Conversion and Monitoring Script
Create a file named pdf_to_docx_automate.py and add the following code. It handles both conversion and folder watching:
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
Step 3: Run the Script and Test
Launch the script from your terminal:
python pdf_to_docx_automate.py
Drop any standard PDF file into the watch_folder directory, and it will automatically be converted to DOCX in the same location.
Limitations
- No built-in OCR for scanned PDFs.
- Complex tables and images frequently end up misaligned.
- You will still need external scheduling via Task Scheduler or cron.
- Debugging can be ongoing, as every PDF variation may present unique challenges.
✅ Advantages:
- Complete code control and customization
- Free to use for simple native PDFs
- Easy integration into existing Python pipelines
❌ Disadvantages:
- No built-in OCR for scanned documents
- Complex tables and images often misalign
- Requires external tools for scheduled execution
- Heavy debugging needed for different PDF layouts
While this custom script offers flexibility, users needing reliable OCR and complex layout preservation should consider dedicated software.
Verification & Recommendations
After conversion, run through this quick checklist:
- Open the DOCX in Word and check that all text is selectable and editable.
- Inspect table structures—rows and columns intact, no unexpected merged cell shifts.
- Scan for
□or random characters that signal garbled text. - Verify that every page from the original PDF made it into the output.
| Use Case | Recommended Tool |
|---|---|
| Quick test on 1–2 simple PDFs | Python pdf2docx script |
| Scanned PDFs or complex layouts | Renee PDF Aide with OCR |
| Batch conversion (50+ files) | Renee PDF Aide (batch + monitoring mode) |
| Scheduled nightly conversions | Renee PDF Aide monitoring mode |
| Full code control + simple PDFs | PyMuPDF + watchdog custom script |
Privacy & speed comparison:
- Python scripts: fully local, but speed varies and there’s no OCR.
- Renee PDF Aide: also fully local, speeds up to 80 pages/min, built-in OCR, and monitoring mode.
For most automated, batch, or OCR-dependent PDF to DOCX in Python workflows, Renee PDF Aide saves you hours of debugging and provides consistent DOCX output.
Frequently Asked Questions (FAQ)
Can Renee PDF Aide handle scanned PDFs that Python scripts cannot read?
Yes, absolutely. Renee PDF Aide features built-in OCR technology with three distinct modes (A, B, and A+B) that can extract text from scanned documents. This is where most Python libraries like pdf2docx fall short, as they lack native OCR capabilities and require additional external tools to process image-based PDFs.
Why does pdf2docx lose my table formatting or column alignment?
The pdf2docx library is primarily designed for text extraction and does not include a sophisticated layout engine. When it encounters complex tables, merged cells, or nested structures, the formatting frequently breaks down. Dedicated conversion software like Renee PDF Aide uses a specialized engine that better preserves the original document structure and formatting.
What is the maximum batch size or page limit in Renee PDF Aide?
Renee PDF Aide has no hard-coded limits on batch size. It can handle hundreds of PDFs and thousands of pages in a single session, with performance depending on your system’s RAM and document complexity. The conversion speed reaches up to 80 pages per minute, making it suitable for large-scale document processing tasks.
Can I convert password-protected PDFs to DOCX with Python or Renee PDF Aide?
Converting password-protected PDFs in Python requires additional libraries, such as pikepdf, to handle password parameters. Renee PDF Aide supports password-protected files natively—simply enter the password when importing the file.
Does Renee PDF Aide work with XFA forms (bank/government PDFs)?
Yes, it fully supports the XFA format. Most Python libraries and other converters fail on XFA documents and produce error pages instead.

Comments
0 comments
Please sign in to leave a comment.